
kaggle UBC OC 대회 기록 02
업데이트:
kaggle Ovarian Cancer Subtype Classification and Outlier Detection

2일차 기록
매일 올리기로 했었지만, 생각보다 매일 올리는게 힘들어서 이제서야 두 번째 기록을 올린다 ㅠㅠ
두 번째 EDA는 첫날 했던 EDA에 이어서 세부사항을 조금 더 확인해 보았다.
EDA
첫날 확인했던 난소함의 하위유형은 각각..
- CC : CC(C). Clear Cell Carcinoma
- EC : Endometrioid Carcinoma
- HGSC : High-Grade Serious Carcinoma
- LGSC : Log-Grade Serious Carcinoma
- MC : Mucinous Carcinoma
이며, 분류 기준은
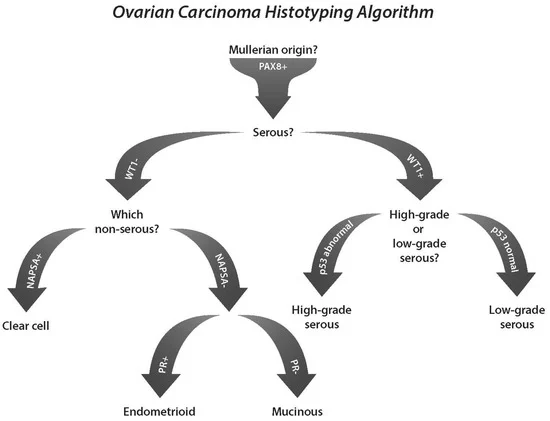
위 이미지와 같다.
Issues in train data
여기까지 간단한 EDA를 진행하였고, resize된 train data를 한 장씩 살펴보고 있었는데, 문제가 있는 이미지가 꽤 많았다.
1. Data imbalane in TMA
train data에는 WSI-image와 TMA-image 두 종류가 있는데, TMA-image는 25장 밖에 존재하지 않는다.
하지만 test data는 약 2천장의 image로 구성되어 있는데, 5:5의 비율로 WSI-image와 TMA-image가 존재한다.
즉, TMA-image의 data-imbalance가 심각하다고 볼 수 있는데, 이 문제는 Class-imbalance 문제가 아니기 때문에, (Horizontal / Vertical) Flip 등의 간단한 Augmentation으로 TMA-image의 수를 늘려주면 어느정도 해결될 것으로 보인다.
일단 이 부분은 직접 모델을 돌려가면서 성능 테스트 후 추가적인 조치를 결정해야 될 것으로 보인다!
2. Wide image with over two samples
좌우로 아주 넓은 이미지 한 장에 두장 이상의 tissue slice가 들어가 있는 이미지들이 꽤 많다.
이 경우에 한 장에 2~3장씩 들어있는 tissue들은 모두 같은 class를 가지고 있기 때문에,
- 여러장 들어있는 tissue slice를 crop해 하나의 이미지에 한 slice만 들어가도록 처리후 하나의 slice만 사용하여 학습.
- 또는 위에서 crop한 모든 slice를 학습에 사용.
- 한 이미지에 여러 slice가 들어있는 이미지를 그대로 resize한 후 학습에 사용.
의 3 가지 방법이 있는데, 1번 혹은 2번 해결방법이 가장 좋은것으로 보인다.
이미지의 수가 많다면 따로 tissue slice를 검출해 내는 모델을 만든 후 해당 영역을 crop해서 사용을 해도 되겠지만, train data의 이미지 수가 그렇게 많지 않기 때문에 수동으로 crop한 후 사용하는게 효율적이라는 생각이 든다.
3. Wrong masking image
이게 가장 큰 문제인데, 현재 tissue slice의 masking이 엉망으로 되어있는 이미지가 꽤나 다수 존재한다.
이 부분은 내가 직접 image를 수정해서 고칠 수 있는 영역이 아니고, discussion을 봤더니 같은 문제로 문의글을 올린 사람이 있었다.
해당 글에 Competition Host가 직접 답글을 달았고, 금방 해당 issue를 수정해 주겠다고 했는데, 5일이 지난 지금 (10/22) 아직도 수정이 되지 않고 있다…
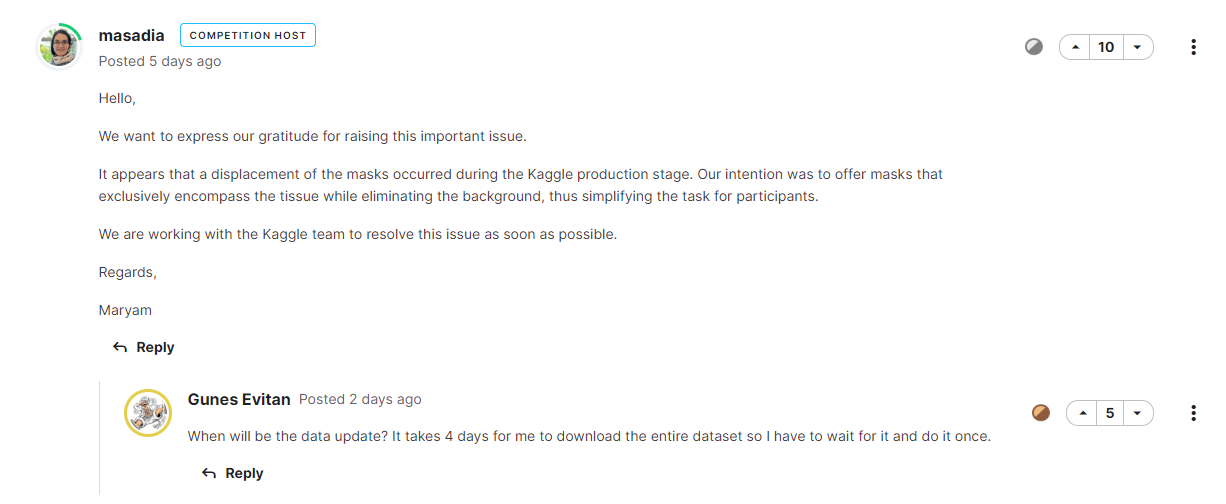
4. PNG
이전의 post에서 적어둔것 처럼, data의 크기가 700GB가 넘어갈 정도로 크기 때문에, 왜 .jpg가 아닌 무손실압축 확장자인 .png를 선택했냐고 따지는 글이 discussion에 올라왔다.
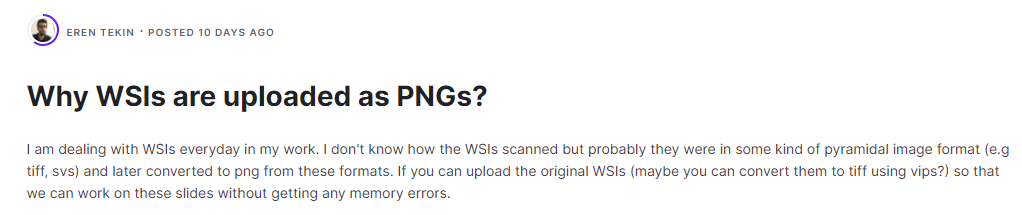
그런데 그 글에 달린 Kaggle Staff의 답변이 가관이다.
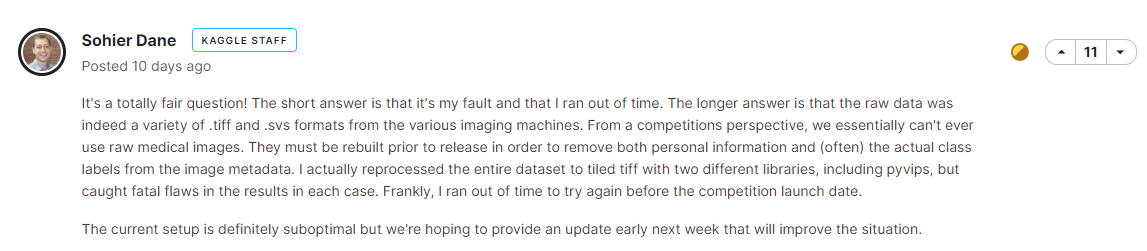

요약하자면, Sohier Dane씨가 .tiff와 .svs format의 medical image의 raw data에는 개인정보나 실제 label등의 정보를 지우고 이미지만 따로 추출해 내는 작업이 필요한데, 작업중 오류 (fatal error)가 났고, 대회 시작 전까지 시간이 없었기 때문에 급하게 .png파일로 올렸다고 한다…;;
여튼 다음주 안으로 문제를 해결해 준다고 하는데, 10일이 지난 지금까지 새 dataset이 올라오지 않고 있다…
So, what now?
그렇다면 지금 시점에서 내가 무엇을 할 수 있는지 생각을 해 보면…
train data에 관해서는 더 이상 손을 댈 수 있는 부분이 없는것 같다.
아직 dataset에 대한 embago도 풀렸다는 안내도 없어서 이미지도 올리지 못하고… ㅠㅠ

우선은 resize외에 아무런 전처리 없이 학습이 가능한 전체 train pipeline(baseline)을 만들어서 학습이 제대로 진행되는지만 확인을 해 볼 생각이다.
댓글남기기