
CV논문리뷰 01 - Alexnet
업데이트:
Abstract
-
ImageNet LSVRC-2010 대회의 1000가지 종류로 분류되는 120만개의 고해상도 이미지를 분류하기 위해 크고 깊은 CNN모델을 훈련시킴. 테스트 데이터에서 기존 sota보다 상당히 나은 top1, top5에서의 에러율을 각각 37.5%, 17.0%를 기록. 신경망은 6천만개의 파라미터, max-pooling 계층을 포함한 5개의 Conv layer와 최종 1000-way의 softmax 계층을 포함한 3개의 FC layer에서 65만개의 뉴런으로 이루어져 있음.
Introduction
-
전에는 레이블된 이미지가 적었음 → 그러나 LabelMe, ImageNet과 같은 레이블된 큰 데이터 셋이 존재 Imagenet과 같은 수 백만개 이미지에서 수 천 개의 이미지에 표현된 객체에 대해 학습하기 위해서는 큰 학습 능력을 갖춘 모델이 필요. 그러나 ImageNet으로도 객체인식 문제를 포괄할 수 없으므로 모델에 없는 모든 데이터를 보완 할 수 있는 사전 지식이 많이 있어야 함.
ㄴ 즉, 모델이 거의 모든 사진에 대해 잘 학습해야 한다는 것.
- CNN을 사용하면 network의 깊이와 폭을 변경하여 용량을 제어 할 수 있고 이미지의 특징에 대해 강렬하고 대부분 정확한 가정을 하는 모습을 보임.
The Dataset
- ImageNet은 다양한 해상도의 이미지를 가진 데이터 세트. 그러나 AlexNet은 일정한 크기를 입력으로 받기 때문에 256 X 256 크기의 이미지로 다운샘플링 작업을 실시하고 각 픽셀에 대해 훈련세트의 평균을 빼는 것을 제외하고는 이외의 전처리 작업은 진행하지 않았고 RGB 값을 갖는 픽셀들로 훈련을 진행함
The Architecture
- ReLU Nonlinearity
- 기존 activation func → tanh 또는 sigmoid
- alexnet activation func → ReLU
- 그 결과 25% training error rate에 도달하는 시간이 6배 가량 빨랐음
- Training on Multiple GPUs
- GPU 2개를 병렬 사용
- GPU 1개를 사용한 것과 비교해 training error를 1~2% 줄이고 시간도 단축함
-
Local Respense Normalization(LRN)

-
검은 도형으로 인해 사이사이에 회색 모양들이 잘 보이지 않음. 이런 현상이 cnn에도 적용된다면 강한 특징들에 의해서 약한 특징이 두드러지지 않을 수 있음. → activation function으로 ReLU를 사용하면 높은 input이 들어와도 그대로 내보내다 보니 강한 특징이 들어왔을 때 같은 현상이 일어날 것임. 주변값에 비해 너무 큰 특정 값에 대해 overfitting되는 것을 막고 일반화하기 위해 LRN사용.
-
현재는 많이 사용되지 않는다.
\[b^i_{x,y} = a^i_{x,y}/ (k+\alpha\sum^{min(N-1,i+n/2)}_{j=max(0,i-n/2)}(a^j_{x,y})^2)^\beta\] \[a^i_{x,y}:\textrm{(x,y)에 존재하는 픽셀에 대해 i번째 커널을 적용하여 얻는 ReLU를 씌운 값}\] \[N:\textrm{레이어에 존재하는 전체 커널 수}\] \[n:\textrm{계산에 반영할 인접 kernel의 범위(hyperparameter)}\] \[k=2,n=5,\alpha=10^{-4},\beta=0.75\]
-
-
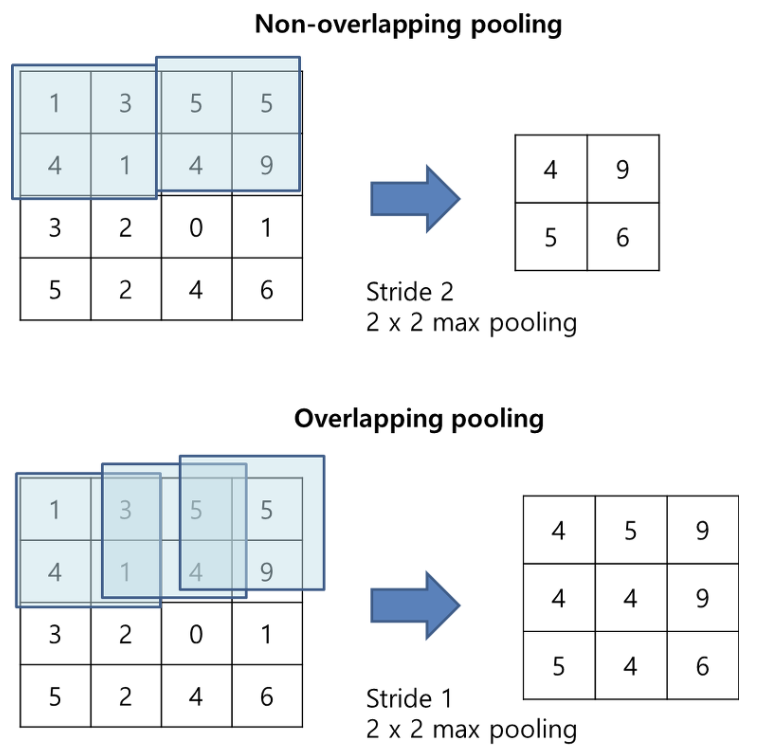
Overlapping Pooling
-
기존 cnn은 filter가 겹치지 않게 pooling을 사용했지만 AlexNet은 겹치도록 하여 max pooling사용
그 결과 error가 감소했음.
-
-
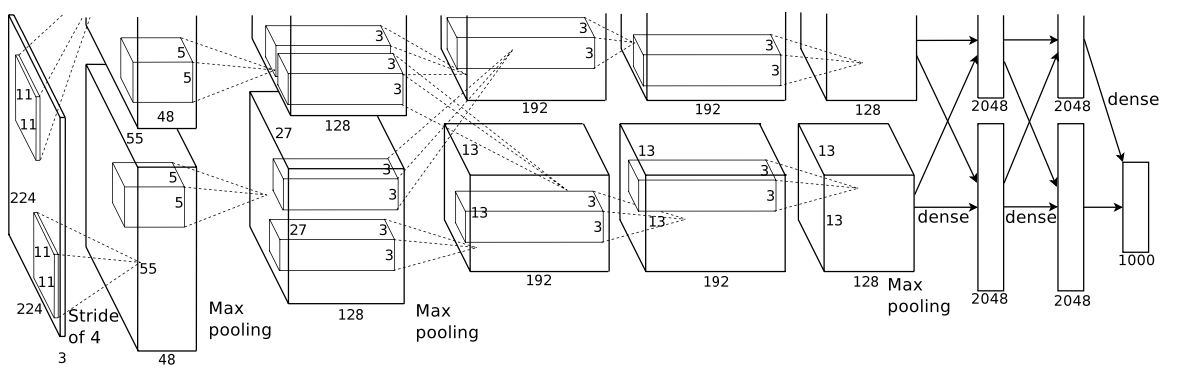
Overall Architecture
-
8개의 layer로 구성 (5 Conv layer + 3 FC layer)
-
마지막 FC layer는 출력층으로 softmax func을 사용하여 1000개의 output출력
2, 4, 5번째 Conv layer는 이전 레이어에서 같은 GPU에 존재하는 kernel map만 input으로 사용
but 3 번째 Conv layer는 모든 kernel map을 input으로 사용
-
Reducing Overfitting
Data Augmentation
- horizontal reflection
- altering the intensities of the RGB channels
PCA을 진행하고 N(0, 1)분포에서 랜덤 변수를 추출한 후, 원래의 픽셀 값에 곱해주어 색상의 변형을 줌.
→ 해당 방식으로 원래 라벨을 건드리지 않고 색상의 변형을 일으킬 수 있음.
Dropout
- 1, 2 번째 FC layer에 50% dropout을 적용시켜 좋은 효과를 봄 but 목표치에 필요한 반복 횟수를 약 두 배로 증가시킴
Results
-
크고 깊은 합성곱 신경망은 오로지 supervised learning을 통해 어려운 dataset에 대해 상당히 훌륭한 결과를 낼 수 있음을 보였음. 이때 Conv layer의 수가 줄어들면 약 2%의 성능 저하가 나타남. 따라서 네트워크의 깊이는 중요한 요소인 것을 확인할 수 있음.
-
딥러닝 깊이를 늘리면서 학습시간이 빠르도록 → ReLU
댓글남기기